
You’re here because you’re joining me on a voyage to actually understand this bloody AI malarky.
We all know there’s a lot of gas blowing about when it comes to AI and its implications.
My approach is to be:
- Open minded
- Curious
- Aware of my bias
So, last time I took a dive into the first part of Google’s AI course. We learned some foundational stuff.
Frankly, on reflection, my key takeaway was really reassuring:
The quality of Generative AI’s output is directly linked to the quality of the user’s input.
Joe Whittaker – 2023
Today, we’re digging a little below the surface and looking at the subject of Large Language Models
I’m approaching this with 3 basic questions:
- Erm. What exactly are Large Language Models?
- Ok. Why does that matter to me?
- What, if anything, should I do with this knowledge?
Grab yourself a cuppa, and settle in for a (hopefully) good read…
What are Large Language Models?
To start with, a Large Language Model (can we agree to call them LLMs for the rest of this article?) is a subset of Deep Learning (I talked about this last time).
They are a model that has a close relationship with Generative AI.
In short, an LLM is a model that can be trained on a large dataset. Google (in a cute move) use the analogy of training a dog to help describe this.

With your average dog, you have a series of commands you’ve trained it to respond to. As it learns these commands, it becomes a good doggo (with a boopable snoot).
However, if you wanted your dog to go on to become a drug sniffer dog, there are ‘special trainings’ needed.
So, this principle is the same with LLMs. They’re trained to a general purpose level with output such as:
- Text classification
- Answering questions
- Summarising documents
- Generating text
These general purposes seem to be where all the current hype is focussed when I browse my Linkedin feed etc.
General purpose LLMs are trained on more data than we can even imagine. Google suggests these models are often trained on Petabytes of data (or one thousand, Million, Million bytes).
Where this starts getting exciting for me is that these same, general purpose models, can be trained on much smaller and specialised data.
So, it’s like taking a sentient being that speaks and understands fluent English and then being able to teach them all about your field (let’s say it’s FMCG marketing). You could teach it all about shopper marketing, above the line activations, digital marketing and social listening and, it would behave like a member of your team.
That’s huge in my mind.
Before I get too carried away thinking through the implications, let’s stick to the task of understanding LLMs.
Google introduces two terms related to LLMS:
- Prompt Design – This is all about providing the model with the relevant instructions and context in order for it to output what you want.
- Prompt Engineering – optimising prompts to use LLMs efficiently with specific and optimised results.
Three main LLMs
Google specifies 3 main types of LLM and cautions us against conflating two of them that seem similar.
Let’s try and wrap our heads around this together.
LLM Type 1 – Generic (sometimes RAW) Language Models
Given a vast database of training data, these models are good at predicting the next word in a sentence.
Here’s a helpful diagram to explain how these work. Google casually drops in some terminology at this point in the course that took me a while to rap my head around. They use a unit called Tokens.
A Token is an atomic unit that is part of a word. These tokens are the basic units LLMs operate in.
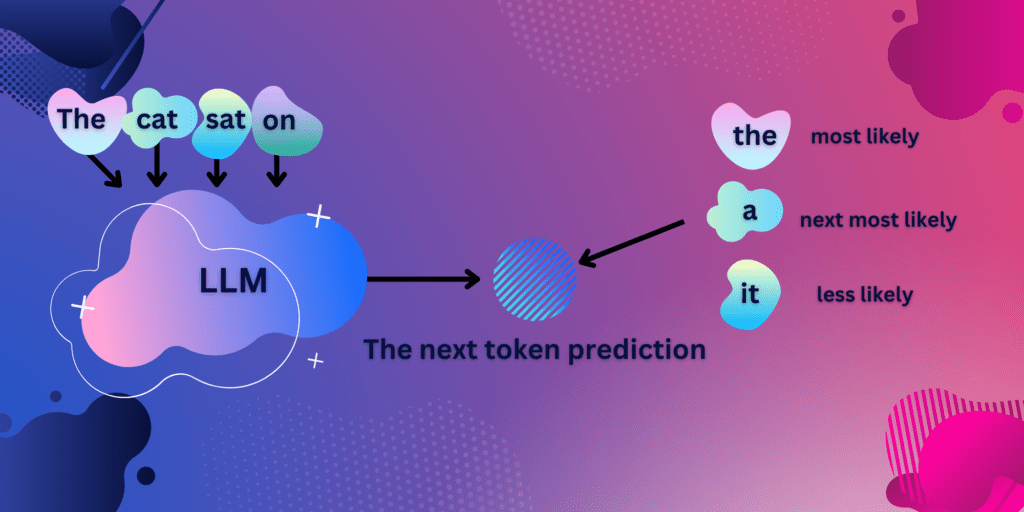
Google uses the analogy of autocomplete in search functionality as a good example of this.
LLM type 2 – Instruction Tuned Models
These models are trained to:
Give a response to the instructions given at the input
Google
If you’re interacting with a Generative AI using an Instruction Tuned LLM (check me out using all these fancy words), you could prompt it by asking it to summarise a text. You could prompt it by asking it to classify the contents of a tweet according to sentiment. You could also ask it to generate you a list of keywords similar to a source word for SEO.
LLM type 3 – Dialogue Tuned Models
In this model, the AI’s output is based on trying to have a conversation with the input.
Google points out that, in reality, this model is a special type of an instruction tuned model. Typically, the model is responding to questions as input.
What does all of this mean?
In a nutshell, what I’ve learned here is an extension of my main takeaway from the first course. The more you tune or train your model, the more specific the tasks your model can perform.
As, I’ve eluded to, the implications are massive.
In theory, you could train an LLM on your brand bible and have it run your community management, adopting your unique tone of voice. You could train the LLM to read tweets from journalists looking for input and have it output only relevant requests to you (we may have built this one in-house, ask us about it). I think the possibilities are almost limitless.
What do you think the implications are?
Do you see it affecting your work life in a tangible way? Do you consider the impact positive or negative, or are you indifferent (well done for reading through to the end if you are)?
I asked a question at the start of this article, “what, if anything, should I do with this knowledge”. I think my answer has to be: play with LLMs. Experiment with different tools and try to understand through play, what might be useful in your context.
I know a few people who are so frightened of it they won’t go near it. I understand where that fear comes from (and am going to be exploring the ethics and future implications of AI in a later article). I’d suggest though, the more we play around with it, the less scary it becomes. You learn of it’s advantages and you learn about its shortcomings.
Ultimately, in a world set to be transformed by AI, those of us who are beginning to understand it and even grasp how to use it will find ourselves at an advantage.
Next time, I’ll be studying the art of responsible AI and looking at image generation.